
This is the second part of a series of articles in which I will be covering a number of handy open-source tools that can help you bring down your compile times. Today’s topic: parallel builds with icecream.
As soon as your project has reached a certain size, compilation times start to become a nuisance. Back in the carefree pre-pandemic days when you were sharing a physical office with a bunch of actual people, you could at least bridge that time by instigating an ad-hoc swordfight with your workmates – but that seems out of the question for the time being. So you need to find effective ways to bring down your compile times such that your productivity is not affected too much by the intermittent delays.
Being an engineer, your probable natural response in any given situation is this: tackle the problem at hand by throwing tools at it – and that’s exactly what this series of articles is about. In part 1, we saw how you can use ccache to memorise your build artefacts so the compiler doesn’t have to do the same thing over and over. In this article, we’re going to harness your readily available hardware infrastructure by dynamically offloading build jobs to multiple machines!
Distributed compilation
The fundamental idea behind distributed compilation is this: while you’re developing software, your machine generally has relatively little work to do most of the time, with intermittent bursts of huge activity whenever you hit the build button. But since source modules can generally be compiled independently of one another, there is vast potential for parallelisation – so why not harness the idle CPU cycles of your workmates‘ systems and pack the compilation workload onto more than one pair of shoulders?
The best-known open-source representative of a distributed compilation system is distcc. distcc consists of a server daemon accepting build jobs over the network, and a compiler wrapper distributing jobs to the build nodes available in the network. distcc has a relatively simple and straightforward architecture but has a number of shortcomings:
- The list of participating build nodes is static and must be known in advance; it is defined in the form of an environment variable. When a node is added or removed, that environment variable must be changed on all clients.
- The scheduling algorithm is relatively naive and offers no built-in way to prioritise more-powerful build nodes over more feeble ones.
- Cross-compilation is not trivial – the correct version toolchain must be preinstalled in the correct version on all build nodes. Heterogeneous infrastructure (for example, different Linux distributions on different machines) can be problematic.
In this article, I will present icecream, an advanced alternative to distcc that offers a number of interesting features.
Icecream: a distributed compile system
Icecream is an open-source project that was initiated and is maintained by the friendly chaps over at SUSE. It originally started out as a fork of distcc, but the two codebases have since diverged significantly. Unlike distcc’s peer-to-peer architecture, an icecream compile farm is built around a central server. On the server runs a scheduler daemon in charge of distributing incoming compile jobs to the available build nodes. Build nodes register and deregister themselves dynamically with the scheduler, so there’s no need to manually maintain a static list of potential compilation hosts.
On the client side, the component that creates new icecream jobs and feeds them to the scheduler is named icecc. Since it is implemented as a compiler wrapper, it can be easily integrated into any existing build system – you’re good to go regardless of whether your project uses CMake, Autotools or plain old Makefiles. Icecream jobs have module granularity; that is, every job entails the compilation of one individual source file (.c/.cpp) into one object file (.o). The final linking step, where the collected object files are linked together into an executable binary or a library, is always carried out locally.
The big picture
A typical icecream deployment consists of the following components:
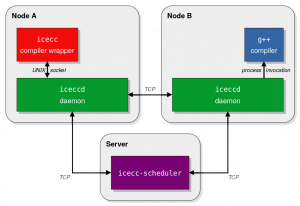
- On one central server: an instance of the
icecc-schedulerdaemon.
- On every build node participating in the Icecream farm: an instance of the
iceccddaemon. This can include the server, but it doesn’t have to.
In the figure on the right, you can see how the various icecream components interact in a setup with two build nodes. Their responsibilities are divided up as follows:
- The compiler wrapper creates new compile jobs. It hands them to the local daemon and eagerly expects the result.
- The daemon accepts jobs and either processes them locally or forwards them to another daemon, depending on the advice from the scheduler.
- The scheduler decides which job should be processed by whom.
Let’s take a look at what happens under the bonnet when the user on Node A runs icecc to compile a C++ source file!
How icecream works
When icecc is executed on node A, it first takes the source file and pipes it through the preprocessor; this way, the .cpp file and the headers #included by it get flattened into a single self-contained stream of text. icecc then proceeds to ask the local daemon for help with the hard part of the work: translating that stream of source code into machine code.
At this point, the iceccd daemon has two options: process the request locally or forward it to another host? This decision is made not by the daemon itself but by a central entity that possesses comprehensive information about the global state of the build farm, namely the scheduler. The scheduler keeps track of how many jobs are currently active, which nodes are present in the network and how they performed in the past. Based on this information, it makes a decision. In our example, the scheduler tells the daemon to forward the job to Node B.
And so the daemon on Node A sends the preprocessed source code along with the user-specified compiler command line to its peer on Node B. In addition, it bundles the local build toolchain into a tarball and hands that tarball to Node B (unless a cached copy is already present there). The daemon on the destination machine unpacks the build environment into a temporary chroot directory. Afterwards, it executes the compiler in the chroot and sends back the result. The answer consists of a thumbs-up or -down, a compilation log (if the compiler produced warnings and/or errors) and the resulting .o file provided compilation was successful.
Heterogeneous environment? No problem.
Through the aforementioned transfer of build-environment tarballs, build jobs are largely self-contained. In particular, this ensures that there are no hidden dependencies between icecream nodes: for instance, there is no requirement to have a specific compiler version present everywhere, because icecream takes care of distributing the correct toolchain automatically.
Hence, icecream not only doesn’t require the locally installed toolchain to be identical on all build nodes – it doesn’t even require a locally installed toolchain at all (on serf-only nodes, that is)! Moreover, it is easy to deploy icecream in heterogeneous environments where different machines run different operating-system distributions or different versions thereof. The only condition is that all participating nodes need to be of the same hardware architecture and based on the same operating-system family – so you can’t mix x86_64 with ARM64 or Linux with macOS.
A big fat security warning!
Before we talk about how to set up and use icecream, allow me to interject an important word of warning: do not deploy icecream carelessly without paying heed to the possible security implications! Icecream itself offers no authentication mechanism and thus anybody can send arbitrary build-environment tarballs to everyone else. Essentially, this makes icecream a remote-code-execution service! The risk is somewhat mitigated by the fact that icecream executes the build toolchain as an unprivileged user in a chroot environment. Still, remember that chroot alone does not even remotely count as a full-blown security mechanism (unlike, say, FreeBSD jails)!
Consequently, your nodes should only ever accept icecream traffic that stems from inside your own organisation. At the very least, your organisation’s firewall should drop any incoming icecream packets from outside the perimeter.
If you need stronger security guarantees and compulsory authentication, I recommend setting up a dedicated VPN between your machines. WireGuard and OpenVPN are good candidates for this. Since icecream’s release 1.3, you can force all icecream traffic to go through the VPN by telling the icecream daemon and the scheduler to listen only on the specific network interface tied to the VPN.
Tutorial: how to use icecream in your project
So how can you get started with setting up your own icecream infrastructure? Actually, it’s not that difficult.
The first step is to pick a designated server for hosting the scheduler component. You should select a machine that is always on and always reachable – at least during office hours. We’ll be referring to that host by the moniker my-icecream-server in the following text.
Next, you need to solve one of computer science’s hard problems: choose a name for your farm. In the examples that follow, we’ll be using my-icecream-network as a generic placeholder.
So much for the preparations. Let’s get going and roll out icecream in your network!
Installing icecream
Icecream is included in your Linux distribution’s package repository, so all you need to do is fire up the package manager. Since all of icecream’s components are usually bundled together in a single package, the installation itself is identical for the server and for client machines.
On Debian/Ubuntu:
$ sudo apt install icecc
On Fedora/CentOS/RHEL:
$ sudo dnf install icecream
Next up, we’ll get things ready to go by editing icecream’s configuration file. Whether you’re about to configure the server or a client machine, the bulk of this process is identical. We’ll get to the differences below.
Common configuration steps
The path and contents of the configuration file vary slightly between Linux distributions. Either way, that file is usually a small shell script that just defines a bunch of variables.
On Debian/Ubuntu, you can find the configuration file under /etc/icecc/icecc.conf and should set the following variables:
ICECC_NETNAME="my-icecream-network" ICECC_SCHEDULER_HOST="my-icecream-server"
On Fedora/CentOS/RHEL, that file is located under /etc/sysconfig/icecream and the configuration variables are prefixed differently:
ICECREAM_NETNAME="my-icecream-network" ICECREAM_SCHEDULER_HOST="my-icecream-server"
What do these two settings do?
- The first line specifies a network name. This is useful if several independent build farms are supposed to coexist within the same physical network.
- The second line tells your
iceccdinstance on which machine the scheduler can be found. This may be superfluous if the development machine is in the same subnet as the build server; in that case, the two may be able to find each other via zeroconf.
Once you have saved the configuration file, restart the icecream daemon to apply the new settings:
$ sudo systemctl restart iceccd.service
The next step will be dependent on whether you’re setting up the server or a client.
Server-specific configuration
When configuring the server, we need to make sure that the scheduler component is activated and its configuration is reloaded:
$ sudo systemctl enable icecc-scheduler.service $ sudo systemctl restart icecc-scheduler.service
Now your server is up and running and the scheduler is ready to assign incoming job requests to nodes!
Client-specific configuration
The scheduler should only ever run on exactly one machine. Multiple schedulers trying to serve the same set of clients tend to confuse icecream in such a way that build machines randomly disappear and pop up again. So, on every machine except for the designated scheduling server, you should stop the scheduler daemon make sure it doesn’t get started again by accident:
$ sudo systemctl stop icecc-scheduler.service $ sudo systemctl disable icecc-scheduler.service
That should be all! The iceccd daemons on your client machines will now register themselves with the scheduler and be ready to accept jobs.
What if I experience connectivity problems?
If a packet-filtering firewall is enabled on your machine, make sure that the following ports are open:
- Scheduler server: TCP 10245, TCP 8765, TCP 8766, UDP 8765
- Development machine: TCP 10245
Enabling icecream in your project
Now that we’re all set up and ready to go, let’s see how we can put our infrastructure to use!
Just like ccache does, icecream ships a number of symbolic links in a system directory. These links are named after the common compiler binaries (gcc, clang, c++ etc.) but point to icecream’s compiler wrapper. To activate icecream, all you have to do is prepend that directory to your PATH environment variable so the wrapper is called instead of the regular compiler binary. Paste the following line into your terminal or add it to your project configuration. Note that the icecream directory must come first because the system searches the PATH from left to right.
On Debian/Ubuntu:
$ export PATH="/usr/lib/icecc/bin:$PATH"
On Fedora/CentOS/RHEL:
$ export PATH="/usr/libexec/icecc/bin:$PATH"
That’s it! Your next build will be distributed with icecream.
To make optimal use of your build farm, you’ll probably need to tell your build system to spawn more parallel jobs than it would normally spawn. By default, most build systems either create no parallel jobs at all, or they launch as many jobs as (logical) CPU cores are available in the local machine. That’s way too few to properly feed our build farm!
Note that you will have to find a suitable trade-off here: if the number of jobs is too low, you waste potential for parallelism; if it is too high, your development machine will suffer excessive memory pressure. In my personal experience, 64 is a suitable job count for machines with 16-32 GiB RAM.
So your build command should look something like this:
$ make -j64
How effective is it?
Okay, so how much will you be able to shave off your compilation times with icecream? This question is hard to answer because icecream’s effective performance depends on a variety of factors. It is heavily influenced by the processing power available, the current system load, the network topology and other things. In addition, the scheduler seems to be somewhat capricious, making slightly strange choices from time to time.
With the infrastructure in my current development project, a large-enough icecream farm of half a dozen reasonably powerful machines is able to yield a speedup by a maximum factor of approximately two to three. That’s far from linear scaling, but it’s still a considerable time-saver. Interestingly, things still function reasonably well when everybody works from home and is only connected via VPN!
One thing to keep in mind is that your team is sharing their idle resources with you, so prepare for a considerable fluctuation in your build times. If the resources at hand are too scarce, maybe you can save a few decommissioned-but-still-usable hardware units from being discarded and add them to your farm as additional build serfs.
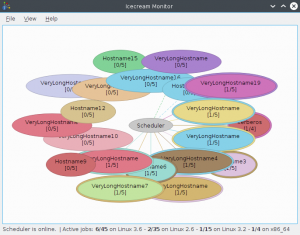
Fancy live monitoring with icemon
Do you fancy getting a colourful real-time overview of the current state of your Icecream cluster? You can do so with the icemon GUI utility, which is available in a separate package.
On Debian/Ubuntu:
$ sudo apt install icecc-monitor
On Fedora/CentOS/RHEL:
$ sudo dnf install icemon
Icemon offers a variety of views that visualise the current state of your build cluster. The default view is the star view (depicted on the right), which represents build nodes as a bunch of blobs arranged around the central scheduler. Active jobs are visualised as rings popping up around the build nodes. When you hit the build button, you can enjoy watching the bouquet explode with activity!
Icemon retrieves all the information it displays by querying the scheduler. It tries to find the scheduler on its own, but in my experience that often doesn’t work out of the box. You can explicitly tell icemon where the scheduler is located by setting the environment variable USE_SCHEDULER to the hostname of the server before calling icemon:
$ USE_SCHEDULER=my-icecream-server icemon
Conclusion
Icecream is a nifty tool that helps you convert your office into a distributed compile farm. It cuts down on your build times by distributing concurrent compile jobs to multiple machines – so drop that sword and get back to work!
That’s all for today, but we’re not done with icecream just yet! In the next part of this series, we’ll see how icecream can be integrated into a containerised build environment. Also, remember ccache from last time? It’s an excellent idea to combine the two to get caching plus distribution at the same time.

- The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 2: icecream - 22. April 2021
- The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 1: ccache - 3. September 2019
Ähnliche Artikel
 3. September 2019 The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 1: ccache
3. September 2019 The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 1: ccache 3. August 2023 Antora and AsciiDoc for Better Documentation
3. August 2023 Antora and AsciiDoc for Better Documentation 29. Juni 2017 Introduction to the Yocto build system
29. Juni 2017 Introduction to the Yocto build system