
This is the first part of a series of articles in which I will be covering a number of handy open-source tools that can help you bring down your compile times. Today’s topic: ccache.
As a software developer, much of your average work day is composed of a succession of recurring develop–build–test cycles: you devise and write new code (or modify existing code); you type make into your terminal or hit the „compile“ button in your IDE; you execute the resulting program and/or tests to see if things work as expected; then you go back to hacking on your code base.

If you’re using a just-in-time-compiled or interpreted language such as JavaScript, Perl or Python, then you’re in the fortunate position that the build step is trivial or happens in the background. Maybe no such step even exists in the first place. But if your code is written in a compiled language such as C++ or C, you know how it goes: the larger and the more complex your project grows, the longer it will inevitably take to build – especially so if your development machine is not a monstrous workstation but a regular laptop. So your computer starts toiling away and unless you have some other small task at hand to bridge the time gap1, all you can do while waiting for the compiler to carry out its job is twiddle your thumbs or mount your office chair and engage your mates in a spontaneous swordfight.
[Drawing by Randall Munroe under the CC BY-NC 2.5 licence.]
Of course, you can tackle this like many performance issues by throwing additional hardware at it: you can place a more potent machine under your desk, or you can set up a dedicated build server for the whole team. But hardware costs money and takes up space and consumes electricity and produces noise and heat… Why not try to make more efficient use of the resources that are already there?
Tools to the rescue!
Fortunately, there are a number of nifty tools out there that can help us with that! We can roughly separate them into two categories that attack the issue from different angles:
- Memorising your build artefacts so the compiler doesn’t have to do the same thing over and over again.
- Harnessing idle processing power by turning the machines in your office into a distributed build cluster.
I’m a big believer in the open-source movement, so that is what I’ll be focusing on. The best-known representative of category 1 is ccache, which we’ll be covering in this article. The second category will be the subject of a future posting.
ccache: a C/C++ compiler cache
„The definition of insanity is doing the same thing over and over and expecting different results.“
ccache was originally developed as a utility for the Samba open-source project. It is a compiler cache that keeps the artefacts produced by past compilation runs in order to speed up subsequent runs. Roughly speaking, if you try to recompile a source file with the same contents, the same compiler and the same flags, the product is retrieved from the cache instead of being compiled anew in a time-consuming step.
How ccache works
This section is intended for the technically interested: we’ll be taking a brief look at the inner workings of ccache. If all you want to know is how to use the tool, feel free to skip to the next section. On the other hand, if you consider this section too superficial and are eager to learn all about the inner workings of ccache, the official documentation has got you covered!
ccache works as a compiler wrapper — its external interface is very similar to that of your actual compiler, and it passes your commands on to the latter. Unfortunately, since ccache needs to examine and interpret the command-line flags, it cannot be paired with arbitrary compilers; it is currently designed to be used in combination with either GCC or Clang — the two big open-source compiler projects.
You invoke ccache just like your regular compiler and pass your long list of command-line arguments as normal. It operates on the level of individual source files, so one call to ccache generally translates one .cpp or .c file into one .o file. For each input source file, the wrapper performs a lookup in its cache. If it encounters a hit, it simply delivers the cached item. In the case of a cache miss, it launches the actual compiler, passing on the litany of command-line arguments; it then inserts the resulting artefact into the cache.
The cache itself is a regular directory on your disk. It is assigned a quota; if that quota is exceeded, old entries get evicted. You can tell ccache which directory to use for the current build. This way, you can maintain different caches for different projects — so compiling a new project B won’t pollute the existing cache of project A.
A look inside
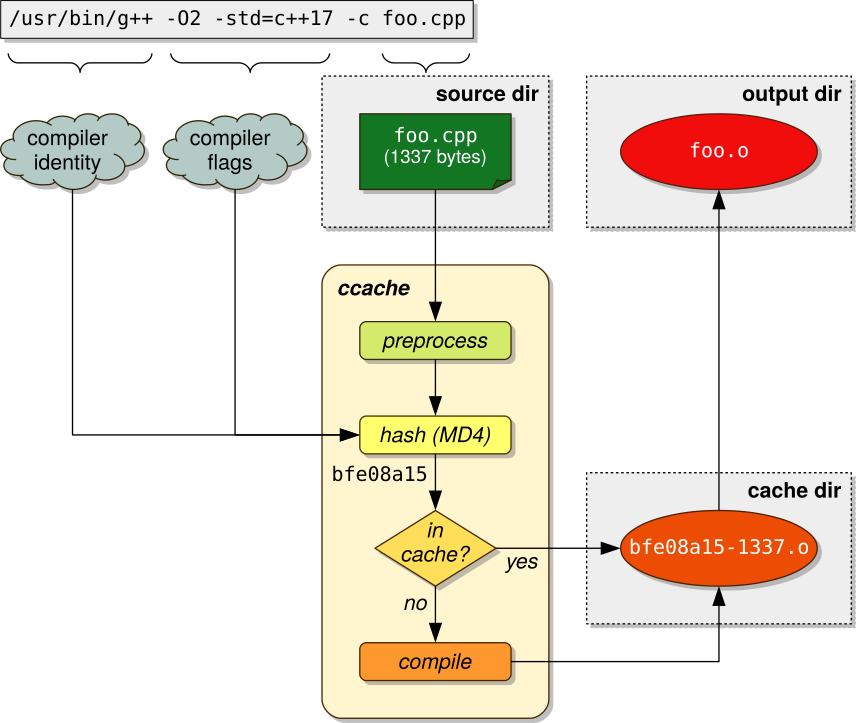
The lookup of cache entries is carried out with the help of a unique tag, which is a string consisting of two elements: a hash value and the size of the (preprocessed) source file. The hash value is computed by running the information that is relevant for the production of the output file through the MD4 message-digest function. Among others, this information includes the following items:
- the identity of the compiler (name, size, modification time),
- the compiler flags used,
- the contents of the input source file,
- the contents of the included header files (and their transitive hull).
The graphic on the right side shows what the approximate work flow looks like.
After computing the tag value, ccache checks if an entry with that tag already exists in the cache. If so, we have a hit: no recompilation is needed! Conveniently, ccache memorises not only the artefact itself but also the console output the compiler printed when translating that artefact — hence, if you retrieve a cached file that has previously produced compiler warnings, ccache will print out these warnings again.
Even more cleverness with the direct mode
While that process already works pretty well in practice, performance may suffer from the fact that every execution of ccache requires a full run of the preprocessor on the source file. This can potentially turn the preprocessor into a severe bottleneck. As a solution, ccache implements an alternative direct mode, which is somewhat more complex but renders the compulsory preprocessor run obsolete. In that mode, ccache computes MD4 hashes for each include header file individually, and stores the results in a so-called manifest. A cache lookup is done by comparing the hashes of the source file and of all its includes with the contents of the manifest; if all hashes match pair-wise, we have a hit. In current versions of ccache, the direct mode is enabled by default.
Wait a moment, isn’t MD4 considered insecure?
If you know a thing or two about cryptography, you may be asking yourself: why use the severely outdated and cryptographically compromisable MD4 hash function? The answer is simple: because MD4 is really fast, and because cryptographic strength is not that relevant in our use case. After all, ccache is not about preventing the forgery of sensitive message contents by a malicious attacker — it’s about detecting and avoiding redundant work. The combination of a 128-bit MD4 hash with a length suffix makes it sufficiently unlikely that you’ll ever hit a tag collision in practice2.
Tutorial: how to use ccache in your project
In the following guide, we will walk step by step through the process of how to use ccache in your project. I assume that your development machine is a Linux box that runs a 64-bit version of either Debian/Ubuntu or Fedora/CentOS/RHEL. If you are on another Linux distribution or another unixoid operating system such as BSD or macOS, the instructions will be analogous but may differ in certain details such as paths. If you are on Windows, you’re on your own.
Installing ccache
Simply install the package that comes with your Linux distribution. Done!
On Debian/Ubuntu:
$ sudo apt install ccache
On Fedora/CentOS/RHEL:
$ sudo dnf install ccache
or
$ sudo yum install ccache
Enabling ccache in your project
The ccache package contains a system directory that contains a number of symbolic links; these links are named after the common compiler binaries (gcc, clang, c++ etc.) but point to ccache’s compiler wrapper. To activate ccache, all you have to do is prepend that directory to your PATH environment variable so the wrapper is called instead of the regular compiler binary. Paste the following line into your terminal or add it to your project configuration. If you are sure that you want to use ccache for everything, you can also add it to your shell configuration file (~/.bashrc, ~/.zshrc etc.). Note that the ccache directory must come first because the system searches the PATH from the left to the right.
On Debian/Ubuntu:
$ export PATH="/usr/lib/ccache:$PATH"
On Fedora/CentOS/RHEL:
$ export PATH="/usr/lib64/ccache:$PATH"
That’s it! Your next build will be accelerated with ccache. Of course, you won’t be able to notice any speedups during the very first run because the cache is initially empty — but subsequent builds will benefit from the cache.
By default, ccache will place the cache in ~/.ccache below your home directory and assign a maximum capacity of 5 GB. If you want to tell it to use a different location, read on.
Optional step: telling ccache which cache directory to use
You may want to set up a separate, individual cache just for your project. This makes sense if you work on several projects and don’t want builds of other projects to evict your precious cached compilation artefacts. Of course, your disk must be large enough to accommodate several caches3. To set up a dedicated cache for your project, simply create a new empty directory in the desired location (say, ~/Projects/myproject/ccache). Then tell ccache about that directory through the CCACHE_DIR environment variable:
$ export CCACHE_DIR="$HOME/Projects/myproject/ccache"
Optional step: configuring the cache
There is a wide variety of settings to configure or tweak your cache(s). I’m not going to start reciting them all here — for a good overview, refer to the official documentation.
Global preferences that are supposed to be set for all caches should go to /etc/ccache.conf. You can override those global settings for an individual cache by defining new values in a file named ccache.conf inside the cache directory. For instance, if you wish to double the capacity of your main project’s cache, edit ~/Projects/myproject/ccache/ccache.conf (if it’s not there, create it) and add the following line:
max_size = 10.0G
Advanced-level stuff: using ccache with Docker
You may be using Docker as an easy way to provide a consistent predefined build environment. In such a configuration, the build is performed within the container.
In order to be effective, your compiler cache should be somewhat long-lived and persistent. Hence, you do not want to couple the state of the cache with the state of the container, which is why you should keep the cache directory outside the container and bind-mount it into the container’s file-system tree. In the following example, we will mount it in a fixed location as /ccache. Note that this is one way to do it — there are several alternatives.
Edit your Dockerfile and have ccache installed in the container. If your container is based on Debian, Ubuntu or a derivative thereof, you need to write something like this:
RUN apt-get install -y ccache
To define the environment variable that tells ccache which cache directory to use, add the following line to the Dockerfile:
ENV CCACHE_DIR "/ccache"
Afterwards, rebuild your container image.
To execute the build, run Docker as usual but tell it on the command line to bind your cache directory to /ccache:
$ docker run (...) --volume=$HOME/Projects/myproject/ccache:/ccache (...)
That should do the trick.
A real-world example
So how effective is ccache in practice? Let’s examine this at the example of a real-world project!
In my current primary project, my team and I support our customer in developing the control software of a product line of medical devices. Our project’s code base is written mostly in C++ and has accumulated well over half a million lines of code in total. Our build system uses CMake in combination with Ninja4, which automatically parallelises the build for the number of CPU cores available. The build environment is containerised with Docker.
On my work laptop, the first compilation run after a checkout takes almost 45 minutes. Now, Ninja is smart and keeps track of the dependencies between source files and build artefacts, so it generally rebuilds only the transitive hull of the artefacts affected by my modifications. But every time I switch between development branches in my working copy, substantial parts of the source tree are recompiled from scratch.
I ran the build on a clean source tree with three different configurations:
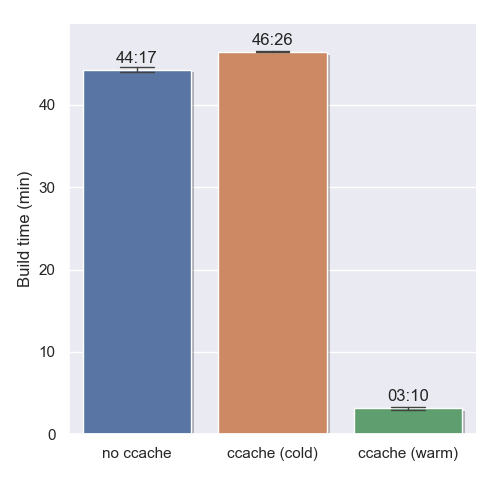
- without ccache,
- with ccache and an empty cache,
- with ccache and a warm cache.
Each build configuration was measured ten times. The times shown are the respective arithmetic means; error bars represent one standard deviation. The results are depicted on the left side.
The bad news is that ccache incurs a small overhead of approximately 5 % when the cache is cold. But here’s the good news: once the cache is warmed up, the time savings are enormous! Of the mere three minutes that remain, the bulk of the time is taken by invocations to the linker, whose work cannot be cached by ccache.
Three minutes is hardly enough to turn your office space into a battle field. Drop that sword and get back to work! Your build is finished.
The end of the road?
ccache is a great tool that can save you a lot of time, but it still leaves room for further improvement. One weakness of ccache is the fact that it operates at the granularity of entire source files. Thus, it is unable to handle cases properly where you, say, change only a comment in a widely included header. Such a modification would actually require no recompilation at all!
A really smart caching solution would base its decisions not on the raw source code but at the abstract syntax tree (AST) that results from parsing that code. A change in a line of code that does not affect the AST can safely be ignored. This has the potential to greatly reduce the number of false cache misses! There is ongoing research into this topic, resulting in a promising prototype named cHash. If you want to know more about it, read the paper!
Outlook
That’s all for today! Stay tuned for part 2, where I will be discussing icecream, a distributing compiler wrapper that can turn your office into a parallel build cluster.
- And as we all know, mental context switches are usually very expensive. ↩
- I can think of a really cool collision attack where a malicious actor poisons your compilation cache with a forged source file that happens to produce the exact same tag as one of your project files. If the cached artefact gets successfully linked into your binary (which means it must also provide the same symbols), then the attacker has managed to inject evil code into your program! But this is a really far-fetched scenario. ↩
- Also, you definitely want both your build directory and the cache to reside on a fast SSD. If you don’t have an SSD in your machine already, go install one now! ↩
- In case you’re not familiar with Ninja: it’s a build system that puts a focus on speed; Ninja assumes that control files are generated rather than hand-written. ↩

- The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 2: icecream - 22. April 2021
- The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 1: ccache - 3. September 2019
Ähnliche Artikel
 15. September 2023 Eclipse Theia: Build your own IDE
15. September 2023 Eclipse Theia: Build your own IDE 22. April 2021 The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 2: icecream
22. April 2021 The C/C++ Developer’s Guide to Avoiding Office Swordfights – Part 2: icecream 17. August 2023 Docs-as-Code
17. August 2023 Docs-as-Code