
Einleitung
Dieser Artikel bildet den dritten und letzten Teil unserer Reise in die Welt der Move-Semantik in modernem C++. Im ersten Teil haben wir betrachtet, wie wir Move-Semantik ab C++11 implementieren und wie wir sie sinnvoll verwenden. Danach haben wir uns im zweiten Teil angeschaut, welche Fallstricke es hierbei zu beachten gibt.
In diesem letzten Teil unserer Blog-Serie werden wir uns mit drei Fragen auseinandersetzen: Wann müssen wir std::move() explizit hinschreiben? Wann sollten wir trotz der Existenz von Move-Semantik als const-Referenz übergeben? Und zum Schluß: Ist der Aufwand, den wir hier treiben überhaupt gerechtfertigt?
Wann genau sollte ich std::move() hinschreiben?
std::move() ist immer dann erforderlich, wenn ein Objekt bereits einen Namen hat und an eine rvalue-Referenz übergeben werden soll. In allen anderen Fällen ist der Compiler schlau genug selbst herauszufinden, dass wir das Objekt als rvalue übergeben wollen. Dies gilt auch dann, wenn wir uns in einer Funktion befinden und der Aufrufer das Objekt, das wir weiterreichen wollen, per rvalue-Referenz an diese Funktion übergeben hat. Bei lokalen Objekten, die aus einer Funktion als Rückgabwert zurückgeliefert werden sollen, ist std::move() nicht erforderlich, hier greifen die Return-Value-Optimization bzw. die Named-Return-Value-Optimization.
Wann sollte ich überhaupt noch by const-Referenz übergeben?
Um diese Frage zu beantworten, müssen wir uns im Detail anschauen was genau bei der Parameterübergabe geschieht – die Short-String-Optimization ignorieren wir hier zur Vereinfachung. Ein Beispiel:
class Foo final {
public:
Foo(const std::string& bar) : m_bar(bar) {}
private:
std::string m_bar;
};
int main() {
Foo f{"bar"};
}
Der Compiler
- stellt fest, dass das
char-Array"bar"nicht zum Typ des Parameters passt, - erzeugt ein
std::string-Objekt für den Parameterbar, - kopiert das
char-Array in diesenstd::string, - erzeugt das
std::string-Objektm_bar, - kopiert den Inhalt von
barinm_bar.
Zur Laufzeit kopiert das Programm die Zeichenkette also zwei Mal um das Objekt zu initialisieren.
Zum Vergleich:
class Foo2 final {
public:
Foo2(std::string bar) : m_bar(std::move(bar)) {}
private:
std::string m_bar;
};
int main() {
Foo f{"bar"};
}
Der Compiler
- stellt fest, dass das
char-Array"bar"nicht zum Typ des Parameters passt, - erzeugt ein
std::string-Objekt für den Parameterbar, - kopiert das
char-Array in diesenstd::string, - erzeugt das
std::string-Objektm_bar, - verschiebt den Inhalt von
barinm_bar.
Hier kommen wir also mit einer Kopieroperation aus.
Wie schaut die Situation aber aus, wenn wir nicht dabei sind ein neues Objekt zu initialisieren, sondern den Inhalt eines existierenden Objekts verändern wollen?
class Foo3 final {
// …
public:
void setBar(std::string bar) { m_bar = std::move(bar); }
private:
std::string m_bar;
};
int main() {
Foo f{"bar"};
std::string s1{"foo"};
std::string s2{"bar"};
f.setBar(s1);
f.setBar(s2);
f.setBar(s1);
}
Hier handeln wir uns für jeden Aufruf von setBar() eine Kopie des jeweiligen Strings für die Parameterübergabe ein.
Der Gegenentwurf
class Foo4 final {
// …
public:
void setBar(const std::string& bar) { m_bar = bar; }
private:
std::string m_bar;
};
legt für die Parameterübergabe keinen neuen String an. Bei der Zuweisung an m_bar ist eine Speicherallokation nur dann notwendig, wenn bar nicht in den Speicher passt, der bereits für m_bar reserviert ist. D.h. eine Kopie des Strings wird in beiden Implementierungsvarianten erstellt. Eine Speicherallokation ist in der zweiten Variante jedoch nur manchmal notwendig, während sie in der ersten Variante immer erfolgt.
Move-Semantik sollten wir also immer dann einsetzen, wenn es um Objektinitialisierung geht, in allen anderen Fällen verwenden wir wie früher auch const-Referenzen für die Parameterübergabe.
Bringt das überhaupt was?
Wir haben nun ein recht gutes Verständnis davon, wie wir Move-Semantik implementieren und verwenden. Außerdem haben wir uns angeschaut auf welche Fallstricke wir dabei beachten müssen.
Was uns noch fehlt, ist eine Antwort auf die Frage, ob es das alles wert ist: Lohnt es sich für uns als C++-Entwickler, uns über Move-Semantik Gedanken zu machen? Lohnt der Aufwand, die Denkarbeit? Oder verschwenden wir hier nur Zeit und Geld unserer Kunden? Dieser Fragestellung wollen wir uns nun zuwenden.
Ein Experiment
Schauen wir uns doch mal anhand eines mit Google Benchmark implementierten Mikrobenchmarks an, wie das Zeitverhalten der Move-Semantik-Implementierung vom Anfang dieses Blog-Artikels aussieht:
constexpr auto test_size = 1024U * 1024U;
constexpr auto repetitions = 200U;
constexpr auto iterations = 100U;
namespace {
void baseline_benchmark(benchmark::State& state) {
for (auto _ : state) {
My11Class foo {test_size};
benchmark::ClobberMemory();
}
}
void copy_benchmark(benchmark::State& state) {
for (auto _ : state) {
My11Class foo {test_size};
benchmark::ClobberMemory();
My11Class bar {foo};
benchmark::ClobberMemory();
}
}
void move_benchmark(benchmark::State& state) {
for (auto _ : state) {
My11Class foo {test_size};
benchmark::ClobberMemory();
My11Class bar {std::move(foo)};
benchmark::ClobberMemory();
}
}
}
BENCHMARK(baseline_benchmark)
->Iterations(iterations)
->Repetitions(repetitions)
->DisplayAggregatesOnly(true)
->ComputeStatistics("stderr", mystderr);
BENCHMARK(copy_benchmark)
->Iterations(iterations)
->Repetitions(repetitions)
->DisplayAggregatesOnly(true)
->ComputeStatistics("stderr", mystderr);
BENCHMARK(move_benchmark)
->Iterations(iterations)
->Repetitions(repetitions)
->DisplayAggregatesOnly(true)
->ComputeStatistics("stderr", mystderr);
int main(int argc, char** argv) {
spdlog::set_level(spdlog::level::off);
benchmark::Initialize(&argc, argv);
benchmark::RunSpecifiedBenchmarks();
benchmark::Shutdown();
return EXIT_SUCCESS;
}Im ersten Benchmark ermitteln wir die Kosten, die durch die Instanziierung des ursprünglichen Objekts entstehen. Danach messen wir jeweils Copy- und Move-Semantik aus. Das Ergebnis kann sich durchaus sehen lassen:
2022-05-17T14:00:32+02:00
Running apps/move_semantics
Run on (8 X 4726.69 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 0.30, 0.37, 0.39
----------------------------------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------------------------------
baseline_benchmark/iterations:100/repeats:200_mean 1.86 ns 2.79 ns 200
baseline_benchmark/iterations:100/repeats:200_median 1.81 ns 1.71 ns 200
baseline_benchmark/iterations:100/repeats:200_stddev 0.673 ns 14.2 ns 200
baseline_benchmark/iterations:100/repeats:200_cv 36.24 % 509.69 % 200
baseline_benchmark/iterations:100/repeats:200_stderr 0.000 ns 0.000 ns 200
copy_benchmark/iterations:100/repeats:200_mean 360588 ns 360577 ns 200
copy_benchmark/iterations:100/repeats:200_median 359116 ns 359116 ns 200
copy_benchmark/iterations:100/repeats:200_stddev 10296 ns 10298 ns 200
copy_benchmark/iterations:100/repeats:200_cv 2.86 % 2.86 % 200
copy_benchmark/iterations:100/repeats:200_stderr 0.750 ns 0.750 ns 200
move_benchmark/iterations:100/repeats:200_mean 3.33 ns 2.69 ns 200
move_benchmark/iterations:100/repeats:200_median 1.78 ns 1.74 ns 200
move_benchmark/iterations:100/repeats:200_stddev 15.1 ns 12.3 ns 200
move_benchmark/iterations:100/repeats:200_cv 452.60 % 456.14 % 200
move_benchmark/iterations:100/repeats:200_stderr 0.000 ns 0.000 ns 200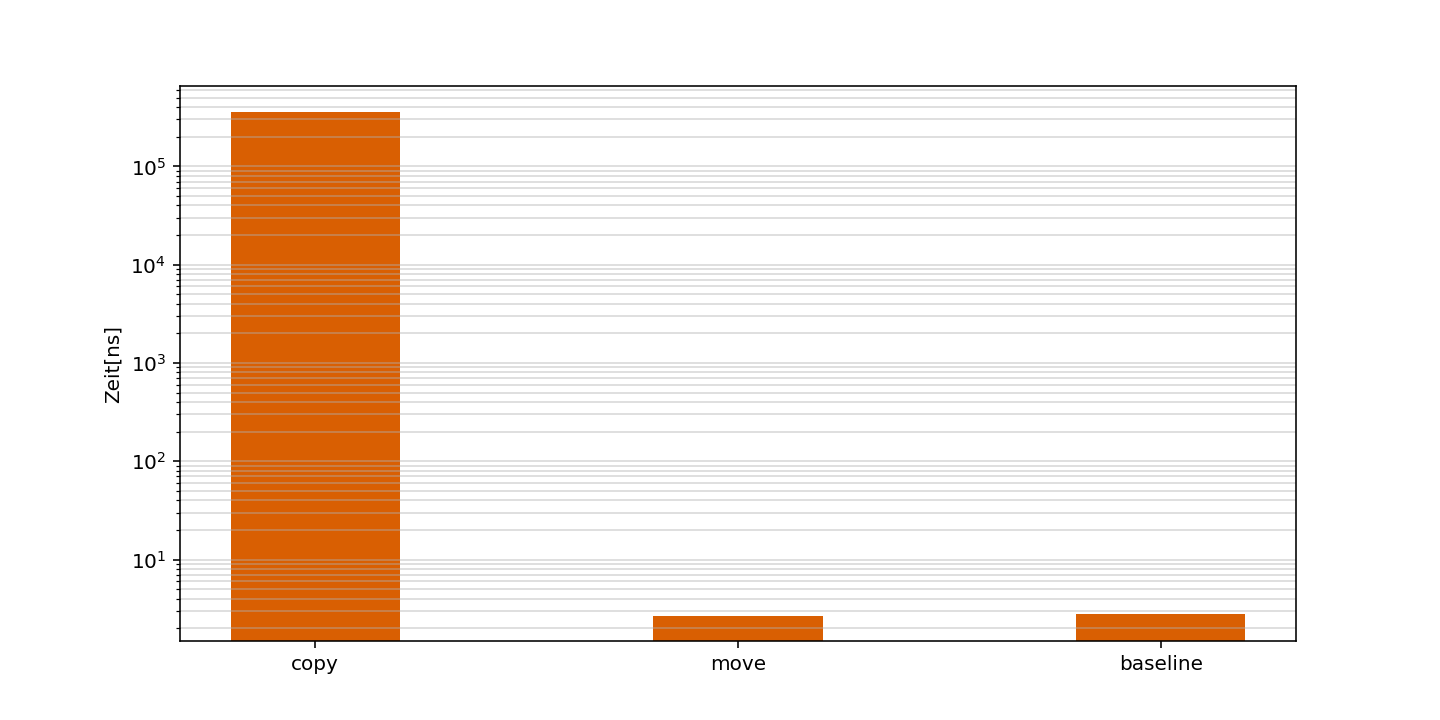
Was sehen wir hier?
- Copy-Semantik verursacht mit 0,36 ms Zeitbedarf erhebliche Kosten.
- Die Kosten für die ursprüngliche Objektinstanziierung sind mit ca. 2 ns Laufzeit vernachlässigbar.
- Die Kosten für Move-Semantik sind von den reinen Kosten der Objektinstanziierung nicht unterscheidbar.
Es lohnt sich also definitiv, Move-Semantik zu implementieren, vorausgesetzt wir sind auf dem performance-kritischen Pfad der Programmausführung unterwegs.
Schluss
Über Move-Semantik gibt es mit Sicherheit noch viel mehr zu sagen, z. B. dazu wie eigentlich std::forward() funktioniert, was Move-Semantik mit std::unique_ptr und std::shared_ptr zu tun hat, welche Spielregeln für Overload-Resolution gelten oder wie man Move-Semantik auf den this-Pointer anwendet.
Das würde aber den Umfang eines Blogbeitrags bei weitem sprengen und wäre eher ein Thema für ein Buch. Ich hoffe aber, dass ich mit diesem Artikel ein bisschen mehr Klarheit in Bezug auf dieses wichtige Sprachmerkmal von C++11 geschaffen habe.
Literatur
- Kurzfassung: Scott Meyers: Effective Modern C++: 42 Specific Ways to Improve Your Use of C++ and C++14. O’Reilly, 2015.
- Langfassung: Nicolai M. Josuttis: C++ Move Semantics: The Complete Guide. Nicolai Josuttis, 2021.
- Nicolai M. Josuttis: The Hidden Secrets of Move Semantics – CppCon 2020.
- Nicolai M. Josuttis: Back to Basics: Move Semantics – CppCon 2021.
- Zum Copy-and-Swap-Idiom: Scott Meyers: Effective C++. Third Edition. Pearson Education, 2005.
Mehr Informationen zu den Themen Software Engineering und Medical Devices findest du in unseren Kompetenzfeldern.
Ähnliche Artikel
 13. April 2017 Medizinprodukteverordnung (MDR) – Is the qualified person a real game changer?
13. April 2017 Medizinprodukteverordnung (MDR) – Is the qualified person a real game changer? 6. April 2017 Cybersecurity in der Medizin – ein Rückblick
6. April 2017 Cybersecurity in der Medizin – ein Rückblick 13. April 2023 Move-Semantik in C++11 – Teil 2
13. April 2023 Move-Semantik in C++11 – Teil 2